ZenML Pipeline Tutorial Part 3: Understanding Artefacts and Adding Inference Steps
Introduction
In this tutorial, we will dive deep into the concept of artefacts in ZenML pipelines. We’ll explain how to define and use them, with a focus on the newly added inference step in an existing pipeline.
What is an Artefact in ZenML?
In ZenML, artefacts represent the output of processing steps within a pipeline. These outputs can be various formats such as datasets, models, metrics, or predictions. Artefacts allow you to track these outputs and reuse them across different workflows. By managing artefacts effectively, you can facilitate reproducibility, versioning, and deployment of your machine learning models.
Different Kinds of Artifact Stores
An artifact store is a structured repository where artefacts generated during machine learning pipelines are stored. Efficient artifact storage and management are crucial for maintaining a seamless workflow in data science projects. There are several kinds of artifact stores that you can employ based on your requirements:
-
File-based Artifact Stores:
- Utilizes local file systems or cloud-based storage solutions like AWS S3, Google Cloud Storage, or Azure Blob Storage.
- Commonly used for storing serialized model files, datasets, and logs in formats such as CSV, JSON, or binary formats.
-
Database-style Artifact Stores:
- Leverages relational databases or NoSQL databases to organize artefacts.
- Artefacts can be stored with metadata, making it easier to search and retrieve models, experiments, and results.
- Examples of such databases include PostgreSQL, MongoDB, or SQLite.
-
Version Control Systems:
- Tools like Git or DVC (Data Version Control) measure and track the versions of artefacts alongside code.
- Especially useful in collaborative environments where multiple data scientists are working on the same project.
-
Cloud-native Artifact Stores:
- Services like MLflow and Weights & Biases provide integrated solutions for storing and managing machine learning artefacts.
- Offer features such as experiment tracking, model registry, and visualization of training metrics.
-
On-premise Solutions:
- For organizations that maintain strict data governance, on-premise solutions could be preferred, utilizing local servers or network-attached storage for artefact storage.
Understanding the different kinds of artifact stores allows you to choose the right method for retrieving, storing, and managing artefacts effectively throughout the ML lifecycle.
Adding an Inference Step to the Pipeline
We recently updated our pipeline to include an inference step, where the trained model is used to make predictions on the test dataset. Below is the updated definition of our training pipeline, along with the inference step:
1. Pipeline Definition (pipelines/training_pipeline.py)
This code defines our updated pipeline, where we integrate the inference step.
import sys
import os
from zenml import pipeline
# Adding the parent directory to the module search path
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
from steps.load_data_step import load_data
from steps.train_model_step import train_model
from steps.evaluate_model_step import evaluate_model
from steps.inference_step import inference_step
@pipeline(name="Tutorial", enable_cache=False)
def training_pipeline():
# Load data
X_train, X_test, y_train, y_test = load_data()
# Train the model
model = train_model(X_train, y_train)
# Evaluate the model
evaluate_model(model, X_test, y_test)
# Inference
predictions = inference_step(model, X_test)
if __name__ == "__main__":
training_pipeline()
2. Inference Step (steps/inference_step.py)
This code snippet shows how we define the inference step, which takes the trained model and makes predictions on the test dataset.
from zenml import step
from sklearn.ensemble import RandomForestClassifier
import numpy as np
@step(enable_cache=False)
def inference_step(model: RandomForestClassifier, X_test: np.ndarray) -> np.ndarray:
"""Inference on test dataset."""
predictions = model.predict(X_test)
return predictions
Loading Artefacts
Once the inference step has been executed, it generates artefacts (i.e., the predictions). To work with these artefacts later on, we can use the following script to load them. Before to load them we need the id of the artifact.
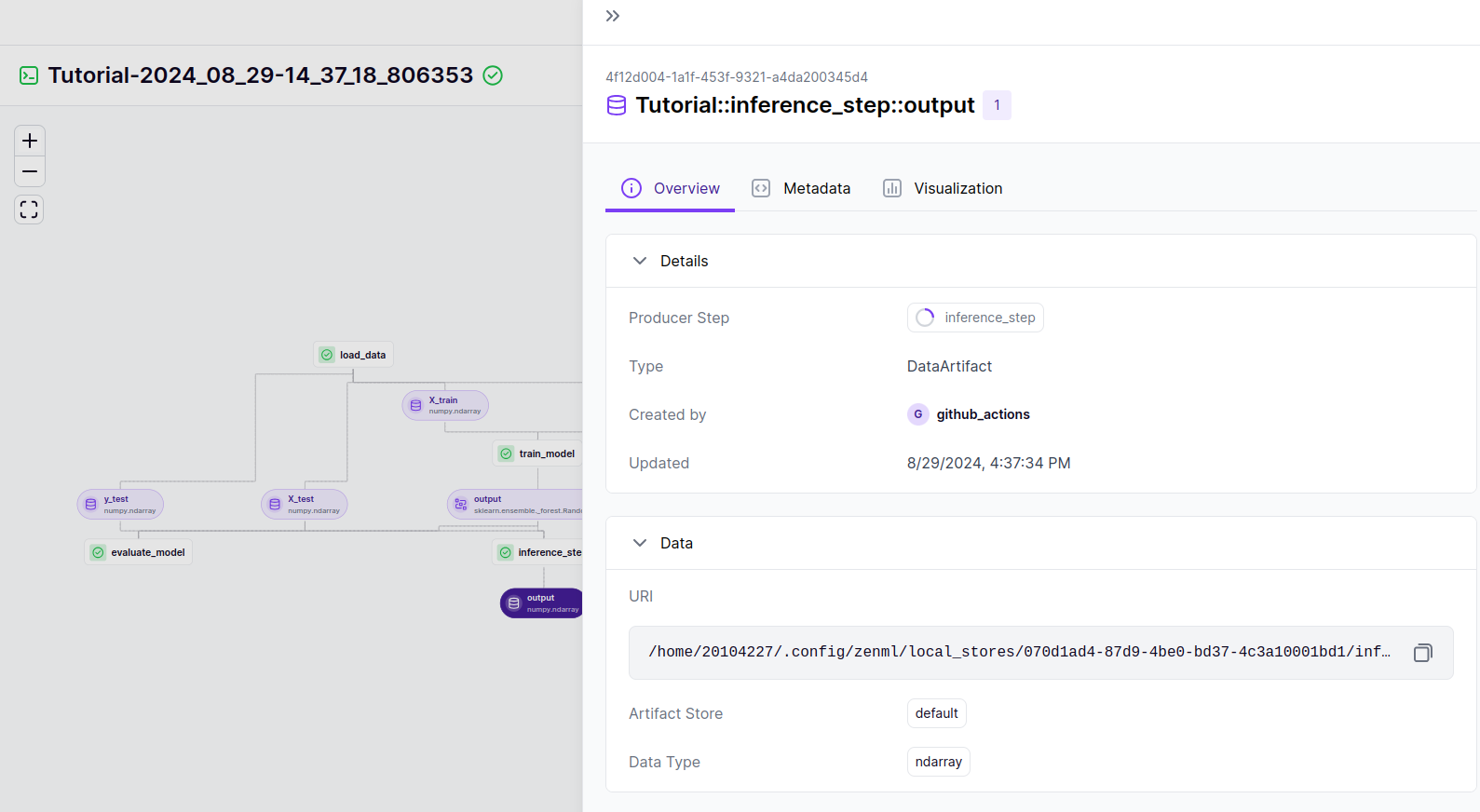
The image shows the details of the artifact produced by the inference_step in a ZenML pipeline. The reference to the artifact is located at the top of the image:
4f12d004-1a1f-453f-9321-a4da200345d4
You can also find it at the bottom of the page in the code section. This reference is crucial for identifying and accessing the specific output generated by the inference_step. It uniquely identifies the artifact within the ZenML pipeline, allowing users to track and retrieve this data for further analysis or documentation.
You can find further information about the artifact in the metadat section.
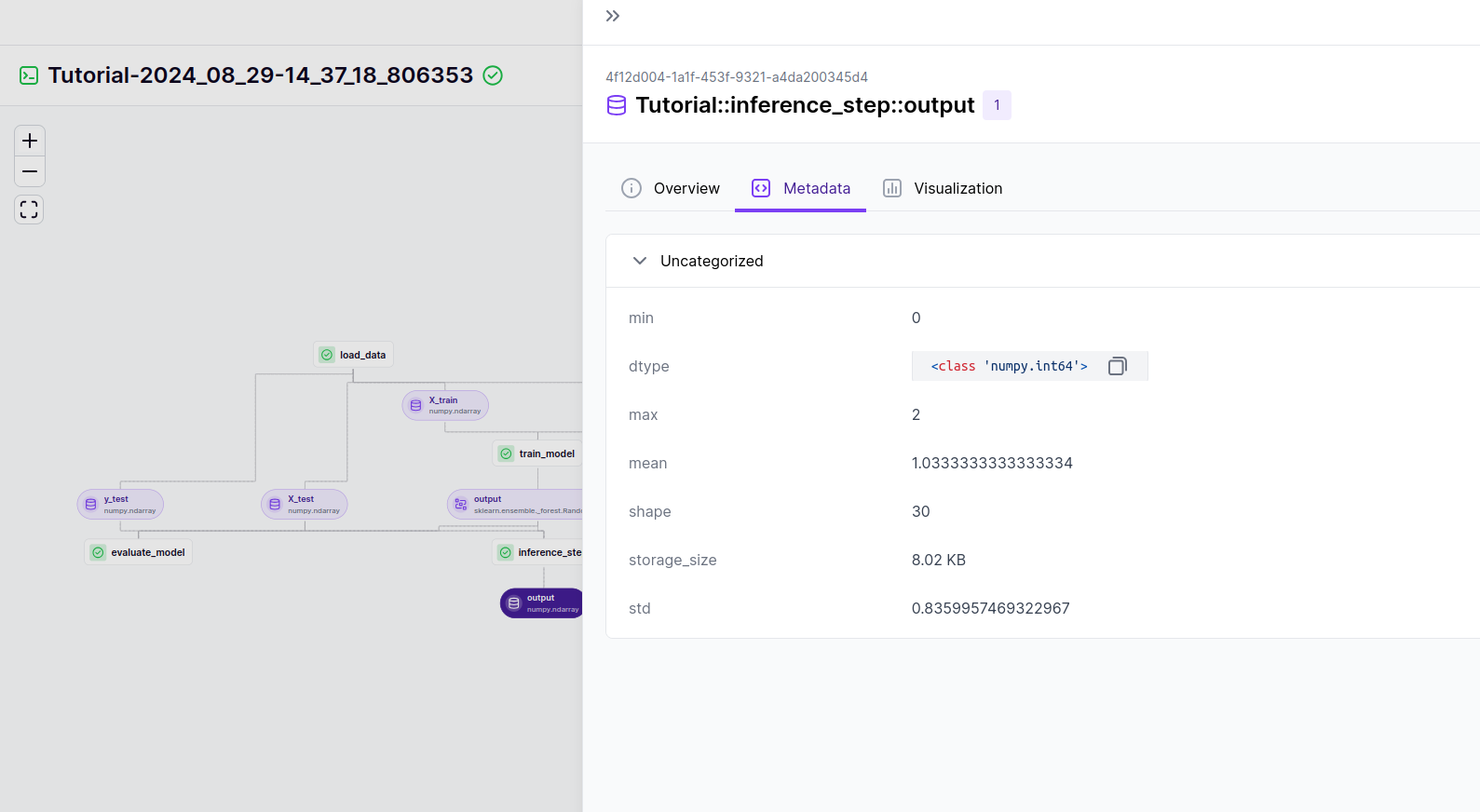
The image provides a detailed view of a ZenML pipeline with a focus on the output of the inference_step. This output is represented as a DataArtifact and includes various metadata that provide insights into the data produced during the inference process.
Key Details from the Artifact Metadata:
In our case we have:
-
URI:
4f12d004-1a1f-453f-9321-a4da200345d4— This unique identifier is associated with the output artifact from theinference_stepin the ZenML pipeline. It helps track and reference this specific output within the workflow. -
Data Type: The data is stored as a NumPy array with a data type of
<class 'numpy.int64'>. This indicates that the predictions or inference results are integers. -
Shape: The shape of the array is
30, indicating that the output consists of 30 elements. This likely corresponds to the number of predictions made by the model during inference. -
Statistical Information:
- Min Value: The minimum value in the predictions is
0. - Max Value: The maximum value in the predictions is
2. - Mean: The average value of the predictions is
1.0333, which suggests that the predicted classes are mostly around 1, with some variation. - Standard Deviation (std): The standard deviation of
0.8359957469322967provides insight into the dispersion of the predicted values around the mean.
- Min Value: The minimum value in the predictions is
-
Storage Size: The artifact occupies
8.02 KBof storage, indicating that the data is relatively small, which is expected given the single-dimensional nature and small size of the dataset used in the inference.
This metadata offers valuable insights into the nature of the predictions made by the model, allowing for a quick assessment of the output characteristics without needing to inspect the raw data directly. This type of information is essential for verifying the model’s performance and ensuring the predictions align with expectations.
Load Artefact Script (load_artefact.py)
This snippet demonstrates how to load a specific artefact from the ZenML client using its unique identifier.
from zenml.client import Client
# Replace with your artefact UUID
artifact = Client().get_artifact_version('4f12d004-1a1f-453f-9321-a4da200345d4')
loaded_artifact = artifact.load()
print(loaded_artifact)
Explanation:
- Client(): This initializes the ZenML client that allows interaction with your ZenML environment.
- get_artifact_version(): We retrieve a specific version of the artefact using its unique identifier.
- load(): This method loads the artefact into memory, allowing you to work with it directly.
Conclusion
In this tutorial, we learned about the significance of artefacts in ZenML pipelines, the various types of artifact stores, and how to integrate an inference step into an existing training pipeline. We also explained how to load these artefacts for further analysis or deployment.
To give more context on the previous steps in the pipeline, feel free to check out the article here.
With this knowledge, you should be well-equipped to utilize artefacts in your ZenML workflows effectively. Happy coding!