Similar and complementary candidates generator
Tutorial: Using Word2Vec for Finding Similar and Complementary Words
In this tutorial, we’ll explore how to leverage Word2Vec to find words that are similar or complementary. We’ll discuss two specific approaches - the IN-OUT approach and the OUT-OUT approach - both of which are useful for various applications, including recommender systems. Our dataset consists of a subset of Wikipedia articles in French, and we’ll guide you through the process of training a Word2Vec model and running inference to discover relatedness among words.
We’ll split this tutorial into two main sections: training the Word2Vec model and using the model for inference.
1. Training the Word2Vec Model
First, we’ll create a Word2Vec model using sentences from a small sample of Wikipedia articles in French.
Step 1: Load and Preprocess the Data
To start, we load a dataset comprising Wikipedia content:
from datasets import load_dataset
from gensim.models import Word2Vec
import multiprocessing
from tqdm import tqdm
# Load a sample subset of the Wikipedia articles
dataset = load_dataset('wikipedia', '20220301.fr', split='train')
dataset = dataset.select(range(10000))
In the snippet above, we utilize the Hugging Face datasets library to fetch a French Wikipedia dump. For efficiency’s sake, we narrow down the dataset to 10,000 articles.
Next, we tokenize the text data into sentences and words using a custom iterator class. This approach reduces memory usage by processing the data lazily:
class TokenizedSentences:
def __init__(self, dataset):
self.dataset = dataset
def __iter__(self):
for article in tqdm(self.dataset, desc="Processing articles"):
text = article['text']
sentences = text.split('.')
for sentence in sentences:
tokens = sentence.strip().split()
if tokens:
yield tokens
Step 2: Configure and Train the Word2Vec Model
Here’s how we set up and train the Word2Vec model:
sentences = TokenizedSentences(dataset)
num_workers = multiprocessing.cpu_count()
# Initialize the Word2Vec model configuration
model = Word2Vec(
vector_size=100, # Dimensionality of the word vectors
window=1, # Context window size
min_count=10, # Ignores words with total frequency lower than this
workers=num_workers,
sg=1, # Skip-gram model
negative=50, # Negative sampling
)
print("Building vocabulary...")
# Build the vocabulary from the sentences
model.build_vocab(sentences, progress_per=10000)
print("Training the model...")
# Train the model on the dataset
model.train(sentences, total_examples=model.corpus_count, epochs=model.epochs, report_delay=10)
# Save the trained model for later use
model.save('word2vec_wikipedia_hf.model')
In this code, we specify parameters essential for Word2Vec, including vector size, context window, and negative sampling count. Following vocabulary building, the model is trained over the dataset, which involves adjusting word vectors to capture semantic similarities.
2. Inference: Finding Similar and Complementary Words
IN-OUT Approach: Find Complementary Words
The IN-OUT approach uses the input and output matrices to identify words that are often found in contexts complementary to a given word.
from gensim.models import Word2Vec
import numpy as np
import faiss
model = Word2Vec.load('word2vec_wikipedia_hf.model')
mot = "français"
if mot not in model.wv:
print(f"This word '{mot}' is not in the vocabulary.")
exit()
mot_index = model.wv.key_to_index[mot]
vecteur_in = model.wv.get_vector(mot)
vecteur_in_norm = vecteur_in / np.linalg.norm(vecteur_in)
vecteurs_out = model.syn1neg
normes_out = np.linalg.norm(vecteurs_out, axis=1, keepdims=True)
epsilon = 1e-10
normes_out[normes_out == 0] = epsilon
vecteurs_out_norm = vecteurs_out / normes_out
dimension = vecteurs_out_norm.shape[1]
index_in_out = faiss.IndexFlatIP(dimension)
index_in_out.add(vecteurs_out_norm)
k = 10
vecteur_in_norm = vecteur_in_norm.reshape(1, -1)
distances_in_out, indices_in_out = index_in_out.search(vecteur_in_norm, k)
In this approach, we normalize the input vector and compare it against normalized output vectors to compute cosine similarities, looking for high scores indicating complementarity.
OUT-OUT Approach: Find Similar Words
The OUT-OUT approach, similar to cosine similarity searches, finds words with similar output vectors.
vecteur_out_mot = model.syn1neg[mot_index]
vecteur_out_mot_norm = vecteur_out_mot / np.linalg.norm(vecteur_out_mot)
index_out_out = faiss.IndexFlatIP(dimension)
index_out_out.add(vecteurs_out_norm)
vecteur_out_mot_norm = vecteur_out_mot_norm.reshape(1, -1)
distances_out_out, indices_out_out = index_out_out.search(vecteur_out_mot_norm, k)
By utilizing FAISS, a library for fast similarity search, we efficiently query top similar or complementary words.
Display Results
Finally, we interpret and display results for both approaches:
mots_vocabulaire = model.wv.index_to_key
print(f"{k} words the most complementary to '{mot}' by IN-OUT approach :")
for idx, distance in zip(indices_in_out[0], distances_in_out[0]):
mot_similaire = mots_vocabulaire[idx]
print(f"{mot_similaire}: Complementarity = {distance}")
print(f"\n{k} words the most similar '{mot}' by using OUT-OUT approach :")
for idx, distance in zip(indices_out_out[0], distances_out_out[0]):
mot_similaire = mots_vocabulaire[idx]
print(f"{mot_similaire}: Similarity = {distance}")
Example Output: Complementary and Similar Words for “français”
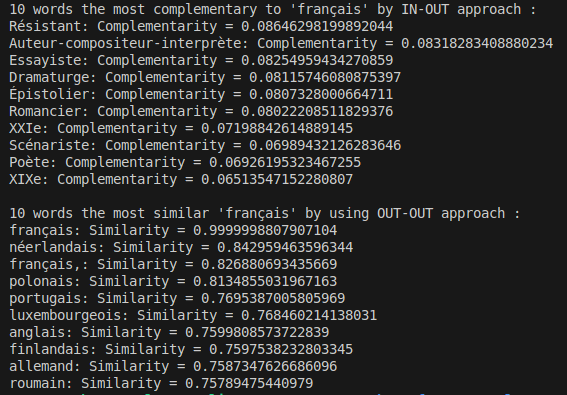
The image above showcases the results obtained using both the IN-OUT and OUT-OUT approaches to analyze the word “français.”
IN-OUT Approach: Finding Complementary Words
This approach identifies the words that are likely to co-occur with “français” in complementary contexts. For instance, the top complementary words include terms like Résistant, Auteur-compositeur-interprète, and Essayiste. Each word is assigned a complementarity score, with Résistant having the highest score of approximately 0.086, indicating a strong complementary relationship.
OUT-OUT Approach: Finding Similar Words
Using the OUT-OUT approach, we determine the words that are semantically similar to “français.” The results include words like néerlandais, polonais, and portugais, with similarity scores provided. As expected, français itself has the highest similarity score of 0.999, while other languages are also closely related, reflecting their conceptual proximity in the dataset.
These results illustrate how Word2Vec can be used not only to find similar words but also to discover words that frequently co-occur in complementary ways, which can be invaluable for tasks such as product recommendation or content generation.
3. Application to Recommender Systems
The techniques described above, particularly the ability to identify complementary words, have considerable implications for the development of recommender systems. While traditional methods often focus on finding similar items, leveraging complementary relationships can significantly enhance the recommendations provided to users.
Enhancing Add-to-Cart Rates
In e-commerce, incorporating complementary item suggestions can influence purchasing behavior. For instance, when a customer views a product, recommending complementary items—such as a phone case when a smartphone is viewed—can create additional value and improve the add-to-cart rates. By applying the IN-OUT approach, we can effectively identify these complementary products based on user behavior and past purchase patterns.
Addressing the Cold Start Problem
Another advantage of this complementary approach is its applicability in tackling the cold start problem in recommender systems. New products or users can lack sufficient interaction history, making it challenging to generate meaningful recommendations. However, by employing a model trained to recognize complementary relationships, we can fill this gap. This allows the system to suggest relevant products to new users based on the items they’ve shown interest in, resulting in a richer, more engaging user experience.
Impact in Practice
The implementation of these complementary recommendations can yield substantial business outcomes. For example, I successfully integrated an algorithm that recommends complementary products, which contributed to an increase in turnover of approximately 1 Million over the course of a year. By continually refining the model with ongoing user data and product interactions, it becomes possible to enhance the precision of these recommendations, thus generating even greater revenue.
Conclusion
In conclusion, leveraging Word2Vec for identifying complementary as well as similar words enables advanced semantic analysis applications. The approaches highlighted can be adapted to various domains, such as product recommendations in e-commerce, leading not only to improved engagement but also significant financial returns.