Recommandation de produits dans le retail
Contexte
Papier de recherche: https://users.soe.ucsc.edu/~pkouki/kouki-recsys19.pdf
Année: 2019
Modèles: Réseaux de neurones siamois & BiLSTM
Sujet: Moteur de recommandations à 2 étapes (Générateur de candidats + Ranker)
Mots-clés: #Embeddings #Item-to-item #Multimodal #Online-recommender-system
Introduction
À travers ce premier article, nous allons étudier la méthode proposée par Home Dépôt afin de recommander des produits sur chaque page de produit. Le moteur de recommandations proposé dans ce papier de recherche est qualifié d’Item-to-item. Ce qui signifie que les données utilisées pour construire le système proviennent essentiellement des produits. Nous sommes dans le cas d’un moteur de recommandation non personnalisé.
Le but de ce moteur est de proposer aux clients un ensemble de produits, que l’on appellera collections, qui sont en lien avec la page produit sur laquelle l’utilisateur se trouve. Ces propositions peuvent être proposées dans des encarts du type “Produits Similaires” ou “Produits complémentaires”.
L’approche proposée par Home Dépôt est classique dans le domaine des moteurs de recommandations. Elle se découpe en deux phases :
- Génération d’un ensemble de candidats de produits (ou CG).
- Le ranking de ces candidats.
Avant de rentrer dans le détail des méthodes utilisées, nous allons voir quelques définitions.
1. Quelques définitions
- $P$ = Ensemble de produits.
$$ P = {p_1,…,p_k} $$
- $A_i$ = Ensemble d’attributs du produit $p_i$. Les attributs sont le titre, la description, la marque, la couleur etc…
$$ A_i = {a_{i,1},…,a_{i,l}} $$
- $C$ = Ensemble des catégories
$$ C = {c_1,…,c_k} $$
- $R$ = Ensemble de relations entre les catégories. Par exemple: $r(Ci,Cj)$ signifie que $C_j$ est une sous catégorie (relation de sous classe partagé) de $C_i$.
$$ R = {r(Ci,Cj), ∀Ci,Cj ∈ C,i < j}. $$
- $h$ = Une hiérarchie représente un ensemble de catégories ordonnées liées par des relations de sous-classe.
$$ h = (C1,C2, …,Ck−1,Ck) ~where~r(Ci,Ci+1) ∈ R, i = 1…k $$ $$ H ~est~l’ensemble~de~toutes~les~hierachies~possible. $$
- La formulation du problème est la suivante:
$$ Pour~ un ~ produit~p_a~ nous~voulons~un~ensemble~de~produits~Pc = {p_{c,1}, …,p_{c,k}} $$ $$ tel~que:~{p_a,p_{c,1},…,p_{c,k}}~avec~les~hierarchies~suivantes~Hc ={h_a,h_{c,1}, …,h_{c,k}} $$ $$ soient~pertinentes~pour~l’utilisateur $$
En général, des règles métier sont utilisées pour réaliser ce genre de contraintes. Dans le cas de ce papier de recherche, la réponse à ce problème est la suivante :
(1) = La couleur des produits doit être la même, et le titre ainsi que la description doivent se ressembler.
$$ (1) ~ ∀p_i ∈ Pc : color_{pi} = color_{pa}, ~ title_{pi} ≈ title_{pa}, ~ description_{pi} ≈ description_{pa} $$
(2) = L’ensemble des produits de la collection doit partager la même catégorie racine entre eux et avoir également la même catégorie racine que le produit “Ancre”.
$$ (2) ~ ∀h_i,h_j ∈ H_c : C_{i,1} = C_{j,1} $$
(3) = L’ensemble des hiérarchies auxquelles les produits de la collection sont rattachés, \H_c\, ne peut pas contenir des doublons. L’idée est de ne pas proposer des produits interchangeables.
$$ ∀h_i,hj ∈ H_c : h_i \neq h_j $$
Maintenant que l’ensemble des définitions est établi, nous allons pouvoir passer au calcul du score permettant la génération d’un ensemble de candidats pour la collection de produits.
2. Génération de candidats
Deux méthodes sont proposées dans le papier de recherche.
- Par l’utilisation de la connaissance métier (Candidate Generator 1 - CG 1)
À cette étape, nous allons établir un lien entre les catégories.
Le processus débute par la récupération de tous les produits fournis par les experts du domaine notés $P_m$. Pour chaque produit, noté $p_{m_i}$ et faisant partie de $P_m$, on identifie la hiérarchie qui lui est assignée, notée $h_i$.
Ensuite, chaque relation entre les produits, notée $r_m(p_{m_i}, p_{m_j})$ et appartenant à de $R_m$, est transformée en une relation entre leurs hiérarchies respectives. Cette transformation donne $Q_m = {q_m(h_i,h_j),…,q_m(h_k,h_l)}$ où $p_{m,i}$ et $p_{m,j}$ sont associés aux hiérarchies $h_i$ et $h_j$ respectivement.
Ce processus génère un ensemble de relations entre hiérarchies, noté $Q_m$. Au sein de cet ensemble, une même relation peut apparaître plusieurs fois.
Après cette étape, nous calculons la probabilité de co-occurrence pour chaque paire de hiérarchies $(h_i,h_j)$. Cette probabilité, notée $Prob_m(h_i,h_j) = \frac{N(q_{m}(h_i,h_j))}{N(h_i)}$ , est calculée en divisant la fréquence de la paire $(h_i,h_j)$ dans $Q_m$ par la fréquence de la hiérarchie $h_i$ dans $Q_m$.
Il est essentiel de souligner que ce calcul de probabilité est effectué uniquement pour les paires de hiérarchies ayant la même catégorie racine.
Voici un exemple concret:
-
Collecte des produits: Supposons que des fournisseurs experts en aménagement d’intérieur nous fournissent une liste de produits pour la cuisine et la salle de bain, par exemple : poêles, spatules, serviettes, robinets, éponges, savons, etc… Cette liste est notre $P_m$. Nous répétons cette étape pour chaque domaine expert. Ici “Cuisine” et “Salle de bains”.
-
Hiérarchie des produits: Chaque produit appartient à une certaine catégorie :
- Ustensiles de cuisine : poêles, spatules
- Petit électroménager : blender, mixeur
- Accessoires de salle de bain : serviettes, savons
- Installations de salle de bain : robinets
- Produits de nettoyage : éponges
-
Relations entre les produits: Supposons qu’à partir des données fournies par les experts, nous déterminons que:
- La spatule et la poêle sont en relation, du fait qu’elles figurent ensemble dans plusieurs collections fournies.
- De même, la spatule est liée au petit électroménager, car on les retrouve conjointement dans certaines collections, comme celles d’une même marque ou dans une cuisine équipée, par exemple.
- Les serviettes et les savons sont également en relation pour des raisons similaires.
Ces relations sont notre $R_m$.
-
Transformation en relations de hiérarchie: Plutôt que de nous concentrer sur les relations entre produits individuels, nous étudions les relations entre leurs catégories respectives. Par exemple, étant donné que la spatule est en relation avec le blender, une relation peut être établie entre “Ustensiles de cuisine” et “Petit Électroménager”.
-
Calcul des probabilités: Supposons que, parmi 100 collections ayant pour catégorie racine “cuisine”, “Ustensiles de cuisine” est mentionné dans 90 collections. Parmi ces collections, 80 associent également “Ustensiles de cuisine” à “Petit Électroménager”:$Prob_m(Ustensiles ~de~cusine, Petit ~Electroménager) = \frac{80}{90}$.
-
Condition importante: Supposons que nous disposions aussi de catégories plus générales telles que “Bricolage intérieur” et “Bricolage extérieur”. Si un produit de la catégorie “Bricolage intérieur” n’a pas de correspondance avec un produit de “Bricolage extérieur”, alors nous ne calculerions pas leur probabilité de co-occurrence, car ils ne relèvent pas de la même catégorie racine.
-
Par l’utilsation des données transactionnelles (Candidate Generator 2 - CG 2)
À cette étape, nous établissons des liens entre les produits en nous basant sur l’historique des achats.
Pour ce faire, nous collectons toutes les transactions en ligne où au moins deux produits ont été acquis au cours d’une période définie, comme une année, par exemple.
Sur la base de ces transactions, nous compilons une liste de tous les produits achetés, que nous désignons $P_p={p_{p,1},…,p_{p,q}}$. On construit ensuite une liste de relations entre ces produits, notée $R_p$ avec $R_p = { rp(pp_i, pp_j), \ldots, rp(pp_k, pp_l) }$. Une relation $r_p(p_{p,i}, p_{p,j})$ signifie que les produits $p_{pR_p,i}$ et $p_{p,j}$ ont été achetés ensemble lors d’une même transaction. Si deux produits sont achetés ensemble plusieurs fois, cette paire apparaîtra plusieurs fois dans $R_p$.
De la même manière que dans la section précédente, pour chaque produit dans $P_p$, on identifie sa catégorie ou hiérarchie. Ensuite, plutôt que de nous concentrer sur les relations entre produits individuels, nous les convertissons en relations entre leurs hiérarchies respectives, générant ainsi un nouvel ensemble de relations, désigné par $Q_p$.
Nous concluons par le calcul de la probabilité. Pour les hiérarchies relevant de la même catégorie générale, nous évaluons la probabilité qu’elles soient co-achetées. Cette probabilité est déduite en divisant le nombre d’occurrences de cette relation de hiérarchie par la fréquence de la hiérarchie elle-même dans $Q_p$.
Voici un exemple concret:
- Collecte des transactions:
- Nous extrayons toutes les transactions où au moins deux produits ont été achetés conjointement.
- Suite à cette extraction, nous recueillons une liste de produits, comprenant des articles tels que : casseroles, spatules, serviettes, robinets, éponges, savons, etc… Cette liste est désignée par $P_m$.
- Nous répétons cette démarche pour chaque domaine expert, par exemple pour les domaines “Cuisine” et “Salle de bains”.
- Hiérarchie des produits: Chaque produit appartient à une certaine catégorie :
- Ustensiles de cuisine : poêles, spatules
- Petit électroménager : blender, mixeur
- Accessoires de salle de bain : serviettes, savons
- Installations de salle de bain : robinets
- Produits de nettoyage : éponges
- Relations entre les produits: Supposons qu’à partir des informations des fournisseurs, on sache que :
-
La spatule et la poêle ont une relation, car elles sont souvent achetées ensemble.
-
Nous savons aussi que la spatule a une relation avec le petit électroménager, car ils sont également achetés ensemble.
-
Les serviettes et les savons ont également une relation, pour la même raison.
Ces relations sont notre $R_m$.
- Transformation en relations de hiérarchie: Au lieu de se concentrer sur les relations entre produits individuels, on examine les relations entre leurs catégories. Ainsi, puisque la spatule est en relation avec le blender, on peut établir une relation entre « Ustensiles de cuisine » et « Petit Electroménager ».
- Calcul des probabilités: Supposons que, sur 100 achats comportant la catégorie racine “cuisine”, 80 mentionnent à la fois “Ustensiles de cuisine” et “Petit Electroménager”, mais que les “Ustensiles de cuisine” apparaissent dans 90 de ces achats: $Prob_m(Ustensiles ~de~cusine, Petit ~Electroménager) = \frac{80}{90}$.
- Condition importante: Pour une catégorie générale comme “Produits pour la maison”, on peut également décomposer la probabilité de co-achat entre des catégories plus spécifiques, telles que “Ustensiles de cuisine” et “Accessoires de salle de bain”, à condition que ces produits appartiennent à la même catégorie générale.
Maintenant que les probabilités entre les hiérarchies sont définies, nous pouvons passer à l’étape d’utilisation des données textuelles liées aux produits.
3. Le Ranker - Utilisation du text embeddings
L’objectif de cette partie est d’exploiter les informations présentes dans le titre et la description du produit. Le réseau de neurones utilisé va permettre de représenter les produits sous forme d’embeddings. La contrainte est la suivante : deux produits auront des embeddings proches s’ils sont considérés comme faisant partie de la même collection.
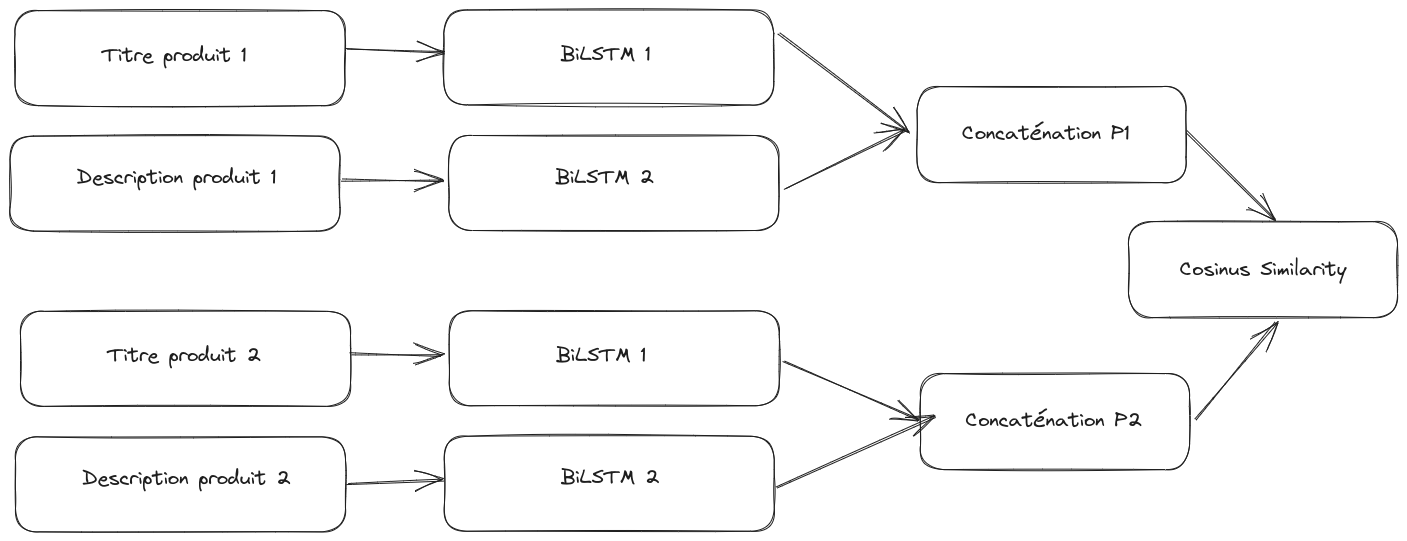
Pour cela, une architecture spéciale de réseau neuronal, appelée “siamese biLSTM”, est utilisée.
Cette architecture se compose de deux biLSTMs : l’un se concentre sur l’analyse de la description du produit tandis que l’autre traite son titre. Après le traitement de ces informations, les résultats obtenus par ces deux biLSTMs sont fusionnés.
Les réseaux siamois sont entraînés pour distinguer deux catégories de paires de produits : celles appartenant à la même collection et celles provenant de collections différentes. Nous avons choisi de ne pas utiliser les données issues des transactions pour cet entraînement, car il est possible que deux produits achetés simultanément n’aient aucun lien entre eux (par exemple : un barbecue et une perceuse).
Pour entraîner le réseau, nous nous appuyons sur les connaissances d’experts du domaine. Lorsque ces experts estiment que deux produits sont de lmême série, nous prenons cette affirmation comme vraie. Pour chaque paire de produits jugés similaires ou complémentaire par les experts, nous générons également plusieurs paires de produits jugés non similaires en sélectionnant aléatoirement d’autres produits dans la base.
4. Le processus de recommendations
Supposons que nous ayons un produit spécifique, appelé “produit ancre”. Pour ce produit, il existe une certaine catégorie ou hiérarchie.
- Identification de la hiérarchie: Pour un “produit ancre” donné, identifiez sa hiérarchie ou catégorie spécifique.
- Calcul des probabilités: Utilisez l’une des méthodes des sections 2.1 ou 2.2 pour évaluer la probabilité que la hiérarchie du produit ancre soit associée à d’autres hiérarchies au sein de la même catégorie principale.
- Sélection des hiérarchies les plus probables: Classez les probabilités du point précédent de la plus élevée à la plus basse, et retenez les hiérarchies ayant les plus fortes probabilités.
- Établissement d’une liste de produits candidats: Pour chaque hiérarchie de haute probabilité sélectionnée, énumérez tous les produits qui y sont associés.
- Extraction des embeddings: Utilisez l’architecture siamoise biLSTM (ou une autre technique pertinente) pour obtenir une représentation numérique du produit ancre et de chaque produit de l’ensemble des candidats.
- Vérification de la correspondance des couleurs: Assurez-vous que la couleur du produit ancre correspond à celle des produits candidats. Si c’est le cas, calculez la similarité entre les embeddings du produit ancre et ceux des produits candidats.
- Création de l’ensemble final: Classez les produits candidats en fonction de leur similarité avec le produit ancre. Sélectionnez le ou les produits ayant la similarité la plus élevée pour les inclure dans l’ensemble final.
Ce processus permet de filtrer efficacement les produits candidats en fonction de leur pertinence par rapport au produit ancre, en utilisant à la fois des informations de catégorie et des embeddings pour déterminer la similarité.
Résultats
3 méthodes ont été étudiées par Home Dépôt. La première, appelée DomExp, utilise les données des fournisseurs. La seconde, nommée DomExpEmb, utilise CG-1 et le ranker basé sur la donnée textuelle. Enfin, la troisième méthode emploie CG-2 et le ranker basé sur la donnée textuelle.
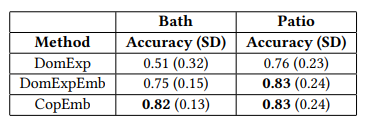
La meilleure option est l’approche couplant le générateur de candidats basé sur les achats et le ranker fondé sur les embeddings textuels. Cela s’explique par le fait que les fournisseurs fournissent des collections de la même marque. Or, les clients n’achètent pas forcément l’ensemble des produits d’une seule et même marque. Il y a donc davantage de relations pertinentes lorsque l’on se base sur les données transactionnelles.
Améliorations
Ce papier présente une méthode basée sur des technologies de 2019 et n’est que la version 1.0 d’un moteur de recommandations basé sur les données produits et l’analyse du panier chez Home Dépôt. Une version plus aboutie est présentée ici.
Voici deux améliorations à mettre en place pour faire évoluer la méthode:
- Ranker: Utilisation d’une architecture basé sur les transfromers ou en fine-tunant un modèle de type BERT sur la donnée du domaine
- Ranker: Ajout de l’embeddings des images. La version 2.0 proposée par Home Dépôt embarque ce nouveau type d’informations