Retrieval-Augmented Generation with LangChain
Large language models hallucinate when asked about facts outside their training data. Retrieval-Augmented Generation (RAG) solves this by fetching relevant passages from a document store at query time and feeding them as context to the model. The result is factually grounded answers without fine-tuning. This article walks through building a complete RAG pipeline with LangChain from document ingestion to final answer.
1. RAG Architecture
A RAG system has two distinct phases.
Indexing (run once, or on document updates):
- Load raw documents.
- Split them into chunks small enough to fit in the LLM context window.
- Embed each chunk with a text embedding model.
- Store embeddings in a vector index.
Querying (run at inference time):
- Embed the user question.
- Retrieve the $k$ most similar chunks from the index using cosine similarity.
- Inject those chunks as context into a prompt template.
- Call the LLM and return its answer.
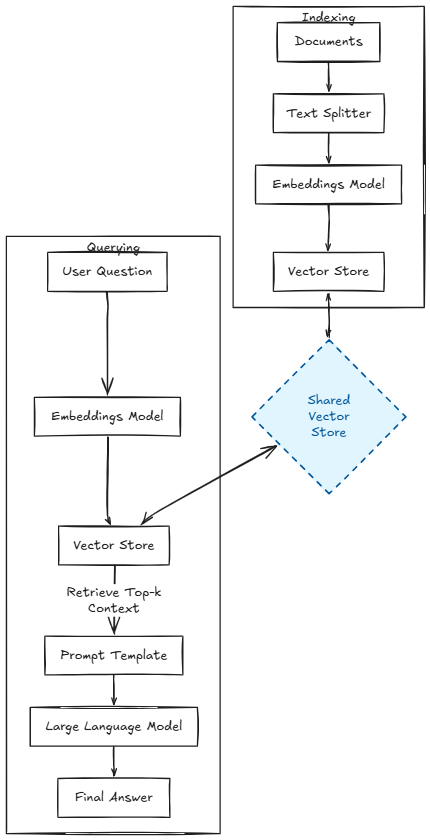 Figure: RAG indexing pipeline (left) and query pipeline (right).
Figure: RAG indexing pipeline (left) and query pipeline (right).
The retrieval step is what keeps answers grounded: the LLM can only say what the retrieved passages allow.
2. Prerequisites
pip install langchain langchain-openai langchain-community faiss-cpu
You need an OpenAI API key exported as OPENAI_API_KEY.
3. Building the RAG Pipeline
Step 1: Load and split documents
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Load a local text file — swap for PyPDFLoader, WebBaseLoader, etc.
loader = TextLoader("docs/ml_glossary.txt", encoding="utf-8")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # characters per chunk
chunk_overlap=50, # overlap avoids cutting sentences at boundaries
)
chunks = splitter.split_documents(documents)
print(f"{len(chunks)} chunks created")
RecursiveCharacterTextSplitter tries to split on paragraph breaks first, then sentences, then words — preserving semantic coherence better than a fixed-size split.
Step 2: Embed and index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Build the FAISS index from chunks (calls the embedding API once per chunk)
vector_store = FAISS.from_documents(chunks, embeddings)
# Persist locally so you don't re-embed on every restart
vector_store.save_local("faiss_index")
For large corpora, replace FAISS with a managed store like Pinecone or pgvector to avoid loading the full index into memory.
Step 3: Build the retrieval chain
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# Reload the persisted index
vector_store = FAISS.load_local(
"faiss_index", embeddings, allow_dangerous_deserialization=True
)
retriever = vector_store.as_retriever(search_kwargs={"k": 4}) # top-4 chunks
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="""Use the following context to answer the question.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question: {question}
Answer:""",
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # "stuff" concatenates all chunks into one prompt
retriever=retriever,
chain_type_kwargs={"prompt": prompt_template},
return_source_documents=True, # inspect which chunks were used
)
chain_type="stuff" works well when $k \times \text{chunk_size}$ stays well below the model’s context limit (128 k tokens for GPT-4o). For larger retrievals, use "map_reduce" or "refine".
Step 4: Query
result = qa_chain.invoke({"query": "What is the difference between precision and recall?"})
print(result["result"])
print("\n--- Sources ---")
for doc in result["source_documents"]:
# doc.metadata["source"] is the original file path
print(f" {doc.metadata['source']} — {doc.page_content[:120]}…")
Exposing source documents is essential in production: it lets users verify claims and builds trust in the system.
4. Evaluating Retrieval Quality
A RAG pipeline is only as good as its retrieval step. Two quick metrics to track:
- Context recall: fraction of ground-truth relevant chunks that appear in the top-$k$ results.
- Faithfulness: whether the LLM answer is supported by the retrieved context (detectable with an LLM-as-judge approach).
The RAGAS library automates both metrics and integrates directly with LangChain output.
Conclusion
RAG is the fastest way to give an LLM access to private or up-to-date knowledge without fine-tuning. The LangChain stack — loader → splitter → embeddings → FAISS → RetrievalQA — handles the plumbing, so you can focus on document quality and prompt design.
Key levers for improving a RAG system:
- Chunk size and overlap: smaller chunks improve precision; larger ones preserve more context.
- Embedding model:
text-embedding-3-largeoutperformstext-embedding-3-smallat roughly 5× the cost. - Retrieval strategy: hybrid search (dense + BM25 keyword) consistently beats pure vector search on domain-specific corpora.
- Re-ranking: a cross-encoder re-ranker (e.g., from
sentence-transformers) applied after retrieval further sharpens relevance.
For a deeper look at how LLMs expose tools and data to external clients, see the article on MCP servers with FastMCP.